- 版本要求
- 系统要求
- 安装 Elasticsearch
- 升级到新的 Elasticsearch 主要版本
- Elasticsearch 仓库索引器
- 启用高级搜索
- 启用自定义语言分析器
- 禁用高级搜索
- 取消暂停索引
- 零停机时间重新索引
- 索引完整性
- 高级搜索迁移
- 极狐GitLab 高级搜索 Rake 任务
- 高级搜索索引范围
Elasticsearch (PREMIUM ALL)
本页介绍如何启用高级搜索。启用后,高级搜索提供更快的搜索响应时间和改进的搜索功能。
版本要求
Elasticsearch 版本要求
对 Elasticsearch 6.8 的支持删除于 15.0 版本。
高级搜索适用于以下版本的 Elasticsearch。
| 极狐GitLab 版本 | Elasticsearch 版本 |
|---|---|
| 15.0 或更高 | Elasticsearch 7.x - 8.x |
| 13.9 - 14.10 | Elasticsearch 6.8 - 7.x |
| 13.3 - 13.8 | Elasticsearch 6.4 - 7.x |
| 12.7 - 13.2 | Elasticsearch 6.x - 7.x |
高级搜索遵循 Elasticsearch 的生命周期结束策略。
OpenSearch 版本要求
| 极狐GitLab version | Elasticsearch 版本 |
|---|---|
| 15.0 或更高版本 | OpenSearch 1.x 或更高版本 |
如果您的 Elasticsearch 或 OpenSearch 版本不兼容,为了防止数据丢失,索引会暂停,并且会在 elasticsearch.log 文件中记录一条消息。
如果您使用的是兼容版本并且在连接到 OpenSearch 后,您会收到消息 Elasticsearch version not compatible,取消暂停索引。
系统要求
Elasticsearch 需要极狐GitLab 系统要求中记录的资源之外的其他资源。
内存、CPU 和存储资源量取决于您索引到 Elasticsearch 集群中的数据量。大量使用的 Elasticsearch 集群可能需要更多资源。根据Elasticsearch 官方指南,每个节点应该有:
- 内存:8 GiB(最小)。
- CPU:具有多核的现代处理器。 极狐GitLab 对 Elasticsearch 有最小 CPU 要求。多核提供额外的并发性,这比更快的 CPU 更有利。
-
存储:使用 SSD 存储。所有 Elasticsearch 节点的总存储大小约为 Git 仓库总大小的 50%。它包括一个主节点和一个副本。
estimate_cluster_sizeRake 任务(引入于 13.10)使用总仓库大小来估计高级搜索存储要求。
安装 Elasticsearch
Elasticsearch 不包含在 Omnibus 包中。您必须单独安装并确保选择您的版本。有关如何安装 Elasticsearch 的详细信息不在范围内。
您可以自己安装 Elasticsearch,或使用云托管产品,例如 Elasticsearch Service(在 AWS、GCP 或 Azure 上可用)或 Amazon OpenSearch 服务。
您应该在单独的服务器上安装 Elasticsearch。不建议在极狐GitLab 所在的相同服务器上运行 Elasticsearch,这可能会导致极狐GitLab 实例性能下降。
对于单节点 Elasticsearch 集群,由于主分片的分配,功能集群健康状态始终为黄色。Elasticsearch 无法将副本分片分配给与主分片相同的节点。
搜索索引在您执行以下操作后更新:
- 将数据添加到数据库或仓库。
- 在管理中心启用了 Elasticsearch。
升级到新的 Elasticsearch 主要版本
- 对 Elasticsearch 6.8 的支持删除于 15.0 版本。
- 从 14.10 升级到 15.0 要求您使用 Elasticsearch 7.x 的任何版本。
升级 Elasticsearch 时不需要更改极狐GitLab 配置。
Elasticsearch 仓库索引器
为了索引 Git 仓库数据,极狐GitLab 使用 Go 编写的索引器。
Omnibus GitLab
从 11.8 版本开始,Go 索引器包含在 Omnibus GitLab 中。
查看索引错误
极狐GitLab Elasticsearch 索引器的错误报告在 elasticsearch.log 文件,和 sidekiq.log 文件,json.exception.class 为 Gitlab::Elastic::Indexer::Error。
索引 Git 仓库数据时可能会出现这些错误。
启用高级搜索
要启用高级搜索,您必须具有对极狐GitLab 的管理员访问权限:
- 在左侧边栏中,选择 搜索或转到。
- 选择 管理中心。
-
在左侧边栏中,选择 设置 > 高级搜索。
要查看高级搜索部分,您需要一个有效的专业版许可证。 - 为您的 Elasticsearch 集群配置高级搜索设置。暂时不要选择 启用 Elasticsearch 的搜索。
- 启用 Elasticsearch 索引 并选择 保存更改。如果索引不存在,这将创建一个空索引。
- 选择 索引所有项目。
- 在确认消息中选择 检查进度,查看后台作业的状态。
-
个人代码片段必须使用另一个 Rake 任务进行索引:
# Omnibus installations sudo gitlab-rake gitlab:elastic:index_snippets # Installations from source bundle exec rake gitlab:elastic:index_snippets RAILS_ENV=production - 索引完成后,选择 启用 Elasticsearch 的搜索 并选择 保存更改。
高级搜索配置
以下 Elasticsearch 设置可用:
| 参数 | 描述 |
|---|---|
Elasticsearch indexing
| 启用或禁用 Elasticsearch 索引并创建一个空索引(如果尚不存在)。例如,您可能希望启用索引但禁用搜索以使索引有时间完全完成。此外请记住,此选项对现有数据没有任何影响,只启用/禁用跟踪数据更改并确保索引新数据的后台索引器。 |
Pause Elasticsearch indexing
| 启用或禁用临时索引暂停。这对于集群迁移/重新索引很有用。仍会跟踪所有更改,但在恢复之前不会将它们提交到 Elasticsearch 索引。 |
Search with Elasticsearch enabled
| 启用或禁用在搜索中使用 Elasticsearch。 |
URL
| 您的 Elasticsearch 实例的 URL。 使用逗号分隔的列表来支持集群(例如,http://host1, https://host2:9200)。 如果您的 Elasticsearch 实例受密码保护,请使用下面描述的 Username 和 Password 字段。或者,使用凭据,例如 http://<username>:<password>@<elastic_host>:9200/。
|
Username
| 您的 Elasticsearch 实例的 username。
|
Password
| 您的 Elasticsearch 实例的密码。 |
Number of Elasticsearch shards
| 出于性能原因,Elasticsearch 索引被分成多个分片。一般来说,应该使用至少 5 个分片,数千万文档的索引需要有更多的分片。在重新创建索引之前,对此值的更改不会生效。您可以在 Elasticsearch 文档中阅读有关的更多信息。 |
Number of Elasticsearch replicas
| 每个 Elasticsearch 分片可以有多个副本。这些是分片的完整副本,可以提供更高的查询性能或针对硬件故障的弹性。 增加此值会增加索引所需的总磁盘空间。 |
Limit the number of namespaces and projects that can be indexed
| 启用此选项后,您可以选择要索引的命名空间和项目。所有其他命名空间和项目都使用数据库搜索。如果启用此选项但未选择任何命名空间或项目,则不会编制索引。 |
Using AWS OpenSearch Service with IAM credentials
| 使用 AWS IAM 授权、AWS EC2 实例配置文件凭证,或 AWS ECS 任务凭证。有关 AWS 托管的 OpenSearch 域访问策略配置的详细信息,请参阅 Amazon OpenSearch 服务中的身份和访问管理。 |
AWS Region
| 您的 OpenSearch 服务所在的 AWS 区域。 |
AWS Access Key
| AWS 访问密钥。 |
AWS Secret Access Key
| AWS secret 访问密钥。 |
Maximum file size indexed
| 查看实例限制文档中的解释。 |
Maximum field length
| 查看实例限制文档中的解释。 |
Maximum bulk request size (MiB)
| 基于 Golang 的索引器进程使用最大批量请求大小,并指示在将负载提交到 Elasticsearch 的批量 API 之前,它应该在给定的索引进程中收集(并存储在内存中)多少数据。此设置应与批量请求并发设置(见下文)一起使用,并且需要适应 Elasticsearch 主机和运行基于 Golang 的索引器的主机的资源限制,无论是来自 gitlab-rake 命令还是 Sidekiq 任务。
|
Bulk request concurrency
| Bulk 请求并发表示有多少基于 Golang 的索引器进程(或线程)可以并行运行,收集数据并随后提交给 Elasticsearch 的 Bulk API。这会提高索引性能,但会更快地填充 Elasticsearch 批量请求队列。此设置应与最大批量请求大小设置(见上文)一起使用,并且需要适应 Elasticsearch 主机和运行基于 Golang 的索引器的主机的资源限制,无论是来自 gitlab-rake 命令还是 Sidekiq 任务。
|
Client request timeout
| Elasticsearch HTTP 客户端请求超时值(以秒为单位)。0 表示使用系统默认超时值,这取决于构建极狐GitLab 应用程序的库。
|
Maximum bulk request size (MiB) 和 Bulk request concurrency 的值会对 Sidekiq 性能产生负面影响。如果您在 Sidekiq 日志中看到增加的 scheduling_latency_s 持续时间,请将它们恢复为默认值。限制可以被索引的命名空间和项目的数量
如果您选中 Elasticsearch 索引限制 下的复选框 Limit the number of namespaces and projects that can be indexed,则更多选项可用。

您可以选择要独占索引的命名空间和项目。请注意,如果命名空间是一个群组,它还包括属于这些子组的任何子组和项目,这些子组也将被索引。
如果所有命名空间都被索引,高级搜索仅提供跨组代码/提交搜索(全局)。在这种仅索引命名空间子集的特定场景中,全局搜索不提供代码或提交范围。这仅在索引命名空间的范围内是可能的。没有办法在多个索引命名空间中编码/提交搜索(当只有命名空间的一个子集被索引时)。例如,对两个群组进行了索引,则无法对这两个群组运行单个代码搜索。您只能在第一个群组上运行代码搜索,然后在第二个群组上运行。
您可以通过编写您感兴趣的命名空间或项目名称的一部分来过滤选择下拉列表。
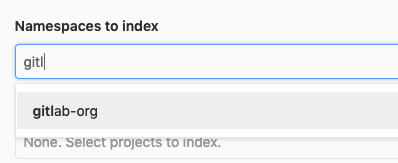
gitlab:elastic:recreate_index 和 gitlab:elastic:clear_index_status。之后,从列表中删除命名空间或项目会按预期从 Elasticsearch 索引中删除数据。启用自定义语言分析器
您可以通过使用 smartcn 和/或 kuromoji 来自 Elastic 的分析插件。
要启用语言支持:
- 安装需要的插件,插件安装说明请参考 Elasticsearch 文档。插件必须安装在集群中的每个节点上,并且安装后必须重新启动每个节点。有关插件列表,请参阅本节后面的表格。
- 在左侧边栏中,选择 搜索或转到。
- 选择 管理中心。
- 在左侧边栏中,选择 设置 > 高级搜索。
- 找到 自定义分析器:语言支持。
- 启用插件支持 索引。
- 选择 保存更改 以使更改生效。
- 触发零停机时间重新索引,或从头开始重新索引所有内容以创建具有更新映射的新索引。
- 上一步完成后启用插件支持 搜索。
有关安装内容的指导,请参阅以下 Elasticsearch 语言插件选项:
| 参数 | 描述 |
|---|---|
Enable Chinese (smartcn) custom analyzer: Indexing
| 使用 smartcn 自定义分析器,为新创建的索引启用或禁用中文支持。
|
Enable Chinese (smartcn) custom analyzer: Search
| 使用 smartcn 字段启用或禁用高级搜索。请仅在安装插件后启用此功能,启用自定义分析器索引并重新创建索引。
|
Enable Japanese (kuromoji) custom analyzer: Indexing
| 使用 kuromoji 自定义分析器为新创建的索引启用或禁用日语支持。
|
Enable Japanese (kuromoji) custom analyzer: Search
| 使用 kuromoji 字段启用或禁用高级搜索。请仅在安装插件后启用此功能,启用自定义分析器索引并重新创建索引。
|
禁用高级搜索
要禁用 Elasticsearch 集成:
- 在左侧边栏中,选择 搜索或转到。
- 选择 管理中心。
- 在左侧边栏中,选择 设置 > 高级搜索。
- 取消选中 Elasticsearch 索引 和 启用 Elasticsearch 的搜索。
- 选择 保存更改。
-
可选。删除现有索引:
# Omnibus installations sudo gitlab-rake gitlab:elastic:delete_index # Installations from source bundle exec rake gitlab:elastic:delete_index RAILS_ENV=production
取消暂停索引
- 在左侧边栏中,选择 搜索或转到。
- 选择 管理中心。
- 在左侧边栏中,选择 设置 > 高级搜索。
- 展开 高级搜索。
- 清除 暂停 Elasticsearch 索引 复选框。
零停机时间重新索引
这种重新索引方法背后的想法是利用 Elasticsearch reindex API 和 Elasticsearch 索引别名功能来执行操作。我们设置了一个索引别名,它连接到极狐GitLab 用于读取/写入的 primary 索引。当重新索引过程开始时,我们会暂时暂停对 primary 索引的写入。然后,我们创建另一个索引并调用将索引数据迁移到新索引上的 Reindex API。重新索引作业完成后,我们通过将索引别名连接到新索引来切换到新索引,这将成为新的 primary 索引。最后,我们恢复写入并恢复正常操作。
通过高级搜索管理触发重新索引
- 引入于 13.2 版本。
- 删除和取消计划索引的功能引入于 13.3 版本。
- 支持在重新索引期间重试的功能引入于 13.12 版本。
要触发重新索引过程:
- 以管理员身份登录您的极狐GitLab 实例。
- 在左侧边栏中,选择 搜索或转到。
- 选择 管理中心。
- 在左侧边栏中,选择 设置 > 高级搜索。
- 展开 Elasticsearch 零停机重新索引。
- 选择 触发集群重新索引。
重新索引可能是一个漫长的过程,具体取决于您的 Elasticsearch 集群的大小。
此过程完成后,原索引计划在 14 天后删除。您可以通过在触发重新索引过程的同一页面上按 取消 按钮来取消此操作。
在重新索引运行时,您可以在同一部分下跟踪其进度。
Elasticsearch 零停机时间重新索引
引入于 13.12 版本。
- 在左侧边栏中,选择 搜索或转到。
- 选择 管理中心。
- 在左侧边栏中,选择 设置 > 高级搜索。
- 展开 Elasticsearch 零停机重新索引,您会发现以下选项:
Slice multiplier
Slice multiplier 计算重新索引期间的分片数。
极狐GitLab 使用手动分片来有效和安全地控制重新索引,允许用户仅重试失败的分片。
Multiplier 默认为 2,适用于每个索引的分片数。
例如,如果此值为 2 并且您的索引有 20 个分片,则重新索引任务将被拆分为 40 个分片。
最大运行分片
最大运行分片参数默认为 60,对应于在 Elasticsearch 重新索引期间允许并发运行的最大分片数。
将此值设置得太高可能会对性能产生不利影响,因为您的集群可能会因搜索和写入而严重饱和。将此值设置得太低可能会导致重新索引过程需要很长时间才能完成。
最佳值取决于您的集群大小、您是否愿意在重新索引期间接受某些降低的搜索性能,以及重新索引快速完成并恢复索引的重要性。
将最近的重新索引作业标记为失败并恢复索引
有时,您可能希望放弃未完成的重新索引作业并恢复索引。您可以通过以下步骤实现此目的:
-
将最近的重新索引作业标记为失败:
# Omnibus installations sudo gitlab-rake gitlab:elastic:mark_reindex_failed # Installations from source bundle exec rake gitlab:elastic:mark_reindex_failed RAILS_ENV=production - 在左侧边栏中,选择 搜索或转到。
- 选择 管理中心。
- 在左侧边栏中,选择 设置 > 高级搜索。
- 展开 高级搜索。
- 清除 暂停 Elasticsearch 索引 复选框。
索引完整性
- 引入于极狐GitLab 15.10,功能标志为
search_index_integrity。默认禁用。- 普遍可用于极狐GitLab 16.4。移除功能标志
search_index_integrity。
检测索引完整性并修复丢失的仓库数据。当范围为群组或项目的代码搜索未返回结果时,会自动使用此功能。
高级搜索迁移
引入于 13.6 版本。
在后台运行重新索引迁移,无需手动干预。这通常发生在向高级搜索添加新功能的情况下,意味着添加或更改内容的索引方式。
要确认高级搜索迁移已运行,您可以检查:
curl "$CLUSTER_URL/gitlab-production-migrations/_search?q=*" | jq .
这应该返回类似于:
{
"took": 14,
"timed_out": false,
"_shards": {
"total": 1,
"successful": 1,
"skipped": 0,
"failed": 0
},
"hits": {
"total": {
"value": 1,
"relation": "eq"
},
"max_score": 1,
"hits": [
{
"_index": "gitlab-production-migrations",
"_type": "_doc",
"_id": "20201105181100",
"_score": 1,
"_source": {
"completed": true
}
}
]
}
}
为了调试迁移问题,您可以检查 elasticsearch.log 文件。
极狐GitLab 高级搜索 Rake 任务
Rake 任务可用于:
- 构建和安装索引器。
- 禁用 Elasticsearch 时删除索引。
- 将极狐GitLab 数据添加到索引。
以下是一些可用的 Rake 任务:
环境变量
除了 Rake 任务,还有一些环境变量可以用来修改进程:
| 环境变量 | 数据类型 | 功能 |
|---|---|---|
UPDATE_INDEX
| Boolean | 告知索引器覆盖任何现有的索引数据(true/false)。 |
ID_TO
| Integer | 告诉索引器仅索引小于或等于该值的项目。 |
ID_FROM
| Integer | 告诉索引器仅索引大于或等于该值的项目。 |
索引一系列项目或特定项目
使用 ID_FROM 和 ID_TO 环境变量,您可以索引有限数量的项目。这对于分段索引很有用。
root@git:~# sudo gitlab-rake gitlab:elastic:index_projects ID_FROM=1 ID_TO=100
因为 ID_FROM 和 ID_TO 使用 or equal to 比较,您可以通过将它们设置为相同的项目 ID 来仅索引一个项目:
root@git:~# sudo gitlab-rake gitlab:elastic:index_projects ID_FROM=5 ID_TO=5
Indexing project repositories...I, [2019-03-04T21:27:03.083410 #3384] INFO -- : Indexing GitLab User / test (ID=33)...
I, [2019-03-04T21:27:05.215266 #3384] INFO -- : Indexing GitLab User / test (ID=33) is done!
高级搜索索引范围
执行搜索时,极狐GitLab 索引使用以下范围:
| 范围名称 | 搜索的内容 |
|---|---|
commits
| 提交数据 |
projects
| 项目数据(默认) |
blobs
| 代码 |
issues
| 议题数据 |
merge_requests
| 合并请求数据 |
milestones
| 里程碑数据 |
notes
| 备注数据 |
snippets
| 代码片段数据 |
wiki_blobs
| Wiki 内容 |