4000 字深度总结!Pipeline 五大性能实践,招招制敌
 毛超
毛超
极狐(GitLab) 研发工程师
太长不读版
你将看到「Pipeline 运行很慢」的问题分析和解决思路,并了解极狐 GitLab CI/CD 解决该问题的最佳实践。
- END
Hold on, hold on! 精彩才刚开始,且听我慢慢道来~
一千个人的心中,就有一千种 DevOps。从 2009 年 DevOps 概念的兴起到今天,衍生出各种各样的工具、规范、流程、原则,足以让人眼花缭乱。
作为软件工程师,我习惯探究一种技术或者概念的核心逻辑,在我看来,DevOps 的核心逻辑就是通过持续集成和持续交付改变团队交付软件的方式,所以持续集成和持续交付就自然成为 DevOps 的两大核心能力,在各种 DevOps 的书籍中也有着重要的篇幅。
极狐 GitLab 作为一体化 DevOps 平台,提供了丰富且强大的 CI/CD 功能,然而根据我在极狐 GitLab 用户微信群中观察到的情况看,依然有研发团队在实践 CI/CD 过程中,出现 「理想很理想,现实很现实」的窘境,碰到各种各样的问题。
今天我就来分享下极狐 GitLab CI/CD 解决典型问题的最佳实践,希望能抛砖引玉,给更多研发团队提供帮助。(下文中的微信群聊都已经过修改,请勿对号入座)
这些问题你遇上过吗?
从上面的群聊中可以看出,大家的 Pipeline 运行的都不快,甚至可以说很慢。如果你也有上述类似的问题,首先要祝贺你,因为只有坚持实践 CI/CD 的团队,才会碰到这种「甜蜜的烦恼」。Pipeline 在日常开发中扮演重要角色,一旦出现性能问题,会极大地影响团队效率,必须加以重视。我相信有些简单的解决思路,例如「性能不够,机器来凑」,可惜这种有钱任性的方式不一定能够解决问题。
作为软件工程师,碰到性能问题,正确的做法应该是查看运行 Log 确定性能瓶颈,分析具体性能问题,最后再进行相应的优化。所以,首先要做的就是查看 Pipeline 的运行 Log,明确每一个 Job 的运行情况,才能定位出某些有性能问题的 Job 并给出解决方案。下面我将分享解决 Pipeline 性能问题的一些最佳实践,供参考~
最佳实践分享
实践一:优化下载外部依赖
一般来说,Pipeline 在运行过程中都会从外部获取依赖,比如拉取项目的依赖包,Java 用 Maven/Gradle,Ruby 用 bundler,NodeJS 用 npm/yarn 等,这时我们就可以在 .gitlab-ci.yml 文件(Pipeline 的定义文件)中使用 cache 关键字,将外部依赖包缓存起来,这样就避免了每次重复下载的动作,可以节省不少时间。cache 的使用也很简单,类似下面的代码:
cache-job:
script:
- echo "This job creates a cache."
cache:
key: third_party_dependency
paths:
- vendor/ruby
- node_modules
在上面的 Job 中,cache-job 缓存了 cache:paths 中指定目录 vendor/ruby 和 node_modules 里面的外部依赖包,cache:key 指定了缓存的唯一标识。这样在 cache-job 运行结束后,会将 cache:paths 中的所有文件打包上传到极狐 GitLab 配置的 cache 地址中,当 Pipeline 再次运行时,会自动下载 cache 中的文件,并存放在 cache:paths ,这样就可以避免重复下载。极狐 GitLab 有更多的 cache 用法,详细使用方法请查看文档 .gitlab-ci.yml 参考。
另外在 docker 大行其道的今天,有不少团队都会使用 docker 来统一运行环境,极狐 GitLab CI/CD 也支持在 Job 中使用 docker,pull docker image 也可能成为性能瓶颈。
如果极狐 GitLab Runner 和极狐 GitLab 在同一个内网中,那么可以使用极狐 GitLab 的 Container Registry 功能,将团队常用的 docker image 上传到极狐 GitLab 中,这样 Pipeline 在下载 docker image 时,Runner 会直接从内网下载 docker image,速度会大幅度提升,详细使用方法请查看文档 GitLab Container Registry。
build_image:
image: docker:20.10.10
stage: build-image
services:
- docker:20.10.10-dind
script:
- echo "Build app"
- docker login -u $CI_REGISTRY_USER -p $CI_REGISTRY_PASSWORD $CI_REGISTRY
- docker build -t $CI_REGISTRY_IMAGE:$CI_COMMIT_SHORT_SHA -t $CI_REGISTRY_IMAGE:latest .
- docker push $CI_REGISTRY_IMAGE:$CI_COMMIT_SHORT_SHA
- docker push $CI_REGISTRY_IMAGE:latest
上面的 Job 演示了 build image 并 push 到极狐 GitLab Container Registry 的过程,使用的变量是极狐 GitLab 预定义的变量 $CI_REGISTRY_USER ,具体介绍请查看文档 预定义变量参考。
实践二:选择性的运行 Job
在项目的日常开发中,很多动作都会触发 Pipeline 运行,比如「功能分支代码更新」,「主干分支代码更新」,「定时运行的性能测试」,而在默认情况下,每次 Pipeline 运行时都会执行所有的 Job,但聪明的你也许已经留意到,上面不同场景中,不是每个 Job 都需要执行。
lint-js: ... # 前端代码静态检查
lint-java: ... # 后端代码静态检查
test-js: ... # 前端测试
test-java: ... # 后端测试
build-package: ... # 打包
performance-test: ... # 性能测试,运行时间较长
deploy-to-qa: ... # 部署到测试环境
deploy-to-production: ... # 部署到产品环境
举个例子,在一个典型的项目中,可能会有上面的 Job,分别完成 静态检查,测试,打包,部署 等工作。在日常开发过程中,当 「功能分支代码更新」时,不需要在 Pipeline 中执行 打包、性能测试、部署 等一系列的 Job,只需要关注 静态检查 和 测试 Job 即可,其他 Job 可以在主干分支的 Pipeline 运行。
而当功能分支合并之后,在「主干分支代码更新」时,再启用 打包、性能测试、部署 等任务,保证主干分支分支的完成 测试,打包,部署 等任务。对于 性能测试 Job,处于成本考虑,可以选择不跟随每次 Pipeline 运行时执行,设置成定期运行(比如一天运行一次)即可。也就是说,在不同的场景中,我们可以选择性的运行某些 Job,忽略另外一些,提高 Pipeline 运行效率。
要实现上述功能,需要使用极狐 GitLab 提供的 rules 关键词,可以定义 Job 合适运行或者不运行,最大限制的控制 Pipeline。
build-package:
stage: build
rules: # 主干分支的 pipeline 才会运行 build-package job
- if: $CI_COMMIT_BRANCH == $CI_DEFAULT_BRANCH
在上面的例子中,我们通过设置 rules:if 配合使用极狐 GitLab Pipeline 的预定义变量,让 build-package Job 只运行在主干分支的 Pipeline 中。
lint-js:
rules:
- if: $CI_COMMIT_BRANCH != $CI_DEFAULT_BRANCH
changes: # js改动 + 功能分支 才运行 lint
paths:
- src/javascripts
- if: $CI_COMMIT_BRANCH == $CI_DEFAULT_BRANCH
# 主干分支需要一直运行 lint,保证质量
对于 lint-js Job 则有两个判断规则,如果不是主干分支(是功能分支)并且改动了 src/javascript 文件夹下的内容,就运行该 Job。另外如果是主干分支也会运行。通过这种设置,既兼顾了功能分支上的运行效率,也能保证主干分支的代码质量,岂不美哉。上面给出的优化策略只是简单的例子,各位读者可以根据项目中的实际情况进行调整。具体 rules 详细介绍请查看文档 指定作业何时使用 rules 运行。
实践三:调整 Job 运行顺序
在默认情况下,Pipeline 中的 Job 是按照 stage 的顺序执行的,假设在 Pipeline 中有 lint 和 test 这两个 stage,那么 test stage 中的 Job 要等待所有 lint stage 的 Job 执行完成后才能开始,这看起来没什么问题,不过依然有优化的空间。
举个例子,在 Pipeline 分别对前端和后端代码做 lint 和 test,那么 lint_frontend Job 执行完后可以直接开始执行 test_frontend Job,不必等待 lint stage 中的 lint_backend 执行完,类似下图。
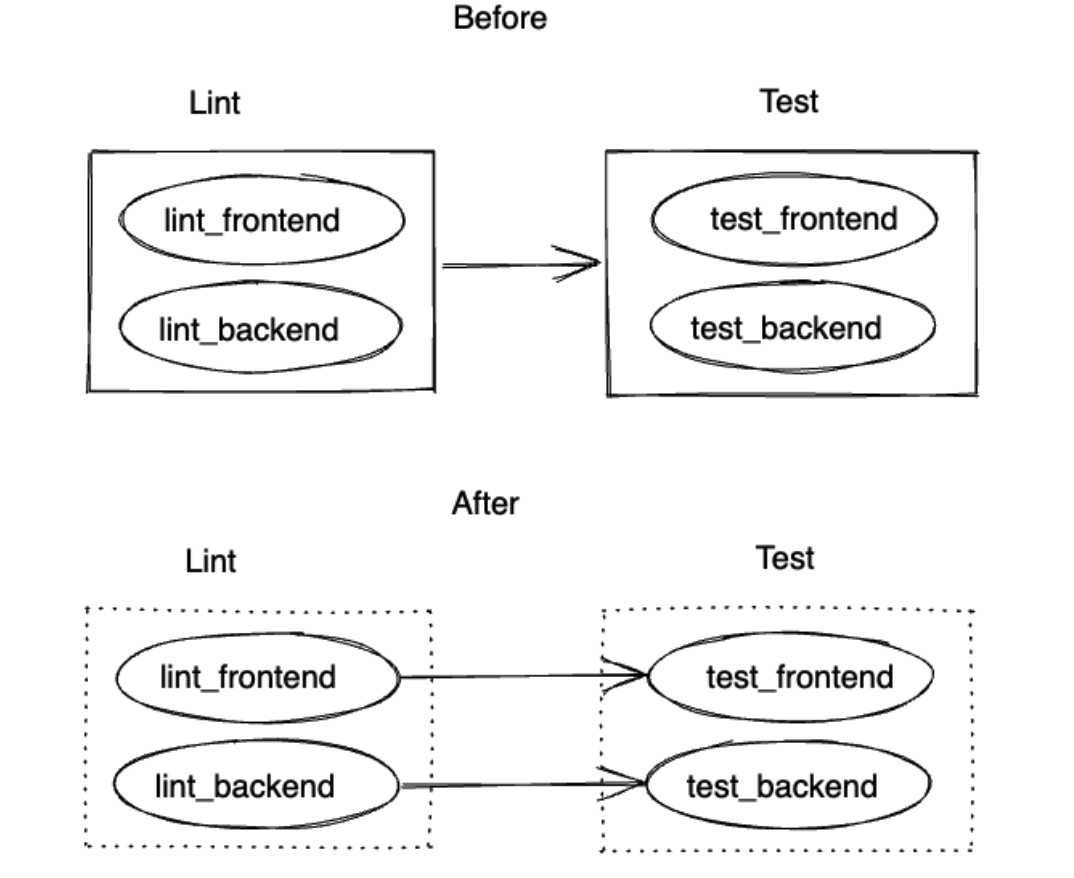
在极狐 GitLab 中,这种 Pipeline 叫做「有向无环流水线 DAG Pipeline」,它能够突破普通 Pipeline 中前序步骤 (stage) 所有任务执行完后,才能执行后续步骤 (stage) 中任务的限制。以 Job 为粒度进行跨 stage 的关联建立,降低任务等待时间的浪费,提升 Pipeline 的执行效率。
lint_frontend:
stage: lint
script: echo "Lint JS ..."
lint_backend:
stage: lint
script: echo "Lint Java ..."
test_frontend:
stage: test
needs: ["lint_frontend"]
script: echo "Running JS Test ..."
test_backend:
stage: test
needs: ["lint_backend"]
script: echo "Running Java Test ..."
上面的代码通过 need 关键字实现 DAG Pipeline,可以看到 test_frontend 依赖 lint_frontend,在 lint_frontend job 结束之后就直接开始运行 test_frontend,不必等待所有 lint stage 都完成。在「生成多平台制品」,「单仓库多模块微服务应用」场景中非常合适,具体请查看文档 有向无环图流水线。
实践四:并行运行 Job
如果某些 Job 的运行时间比较长,该如何优化呢?比如测试 Job,不管是单元测试还是集成测试,虽然运行单个测试速度很快,但数量积累到一定程度之后,往往意味着需要较长的运行时间(当然我也见过十年系统没有一个自动化测试的,我只能祝它好运)。这种情况下可以使用 parallel 关键字,将运行时间较长的 Job 拆分成多个并行运行的 Job ,可以大幅度提升 Job 运行效率。
不同的技术栈有不同的方法来实现并行化测试,我这里举一个 ruby 的例子,下面 test Job 被拆分成 3 个独立的 Job 运行,每个 Job 在运行测试时,会使用 semaphore_test_boosters ,接受参数 $CI_NODE_INDEX/$CI_NODE_TOTAL ,这是每个独立的并行 Job 的标识。当然并行化测试并不是一个简单的设置,还需要考虑给并行测试 Job 分配对应的数据库,缓存等组件,才能真正保证测试并行运行。另外还有一个前提需要满足,给极狐 GitLab 配置多个 runner,否则有再多的 Job 只有一个 runner ,那 Job 依然是顺序执行的。具体可以请查看文档 Plan and operate a fleet of shared runners。
test:
parallel: 3
script:
- bundle exec rspec_booster --job $CI_NODE_INDEX/$CI_NODE_TOTAL
除此之外,在进行并行化测试时,有一个非常有趣的问题,如何把运行时间不同的测试合理分配到不同的 Job 中。在极狐 GitLab 项目中,我们使用 knapsack 进行测试任务的划分,保证测试运行的总体时间最优,感兴趣的读者可以详细了解。
实践五:拆分复杂的单条 Pipeline 为多条 Pipeline
如果使用了上面的方法,依然无法将 Pipeline 优化到一个满意的结果,那可能不是 Job 不够快,而是 Job 实在太多了。
这里我建议可以考虑将当前 Pipeline 进行拆分,拆分 Pipeline 指的是把原本在一条 Pipeline 运行的任务,拆分成多个 Pipeline 顺序执行。拆分 Pipeline 和重构代码方式非常类似,参考「高内聚、低耦合」原则,按照 stage 进行分类,把关联比较紧密的 stage 内聚成一个 Pipeline,关联较弱的 stage 就分开,这样就能得到多个 Pipeline 了。
将一个复杂的 Pipeline 转换成多个 Pipeline 后,可以利用极狐 GitLab trigger 关键字 将多个 Pipeline 连接起来,保证上游 Pipeline 运行结束后触发下游 Pipeline 的运行。在极狐 GitLab 中,有「父子 Pipeline」和「多项目 Pipeline」两种模式。父子 Pipeline 可以在同一项目中启用多条 pipeline,而多项目 Pipeline 会把不同项目的 Pipeline 关联起来。本质上讲,这两种方式都是在降低单条 Pipeline 的复杂度,提升单条 Pipeline 的执行效率。
比如下面的例子中,我们把 lint,test,build-image 放到主 Pipeline 中,将 performance-test ,integration-test,deploy stage 放到子 Pipeline 中,这样做即可以保证主 Pipeline 的执行效率,一定程度上也增加了 Pipeline 的成功率。当主 Pipeline 执行完成后,可以用 trigger:include 触发同一项目的子 Pipeline,或者用 trigger:project 触发拆分到其他 project 中的 Pipeline。整体来讲 Pipeline 执行的 Job 没有减少,只是分阶段执行了而已。详细介绍请查看文档 下游流水线。
# 原有 .gitlab-ci.yml
stages:
- lint
- test
- build-image
- integration-test
- performance-test
- deploy
# 拆分后的主 pipeline .gitlab-ci.yml
stages:
- lint
- test
- build-image
- downstream-pipeline
# 场景一:触发当前项目中的子 pipeline
trigger-child-pipeline:
stage: downstream-pipeline
trigger:
include: path/to/child-pipeline.gitlab-ci.yml
# 场景二:触发其他项目中的 pipeline
trigger-multi-project-pipeline:
stage: downstream-pipeline
trigger:
project: my-group/downstream-project
总结
看到上面五种实践,你是不是已经一拍大腿准备开干了?先别着急,再听我说两句。每个项目的情况都有所不同,不能生搬硬套到自己的项目中,还是需要根据实际情况进行分析和尝试,才能找出最优解。
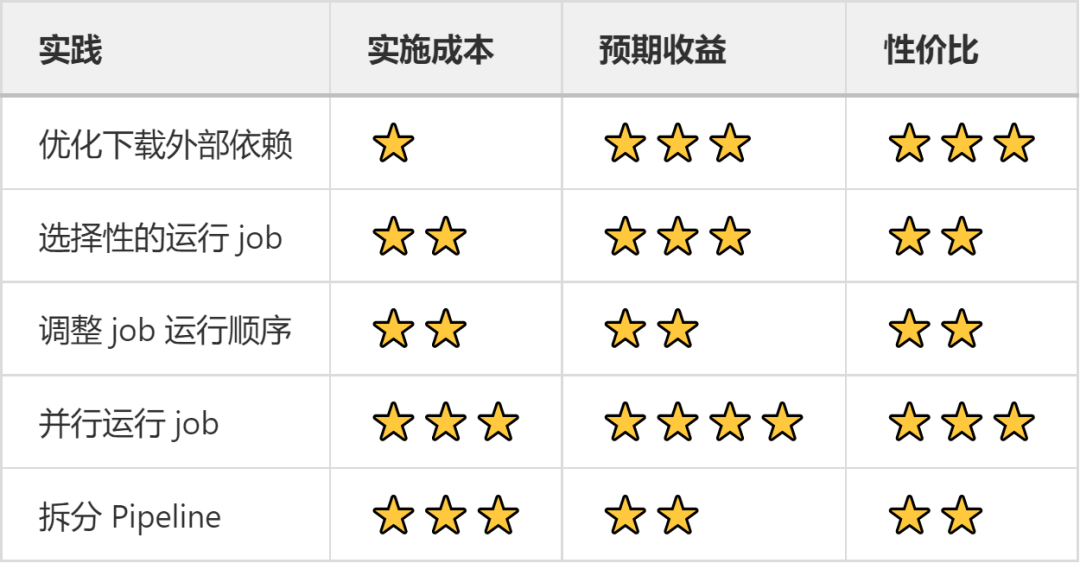
另一方面,上面五种实践「实施成本」和「预期收益」截然不同,所以我总结了下面的表格,你可以从你心中的最高性价比实践开始尝试,循序渐进的优化你的 Pipeline。
团队在实践 DevOps 的过程中,肯定不会一帆风顺,需要持续投入资源,针对问题做度量,分析,实施,才能真正确保实践落地改变团队。
想要把 CI/CD 最佳实践讲透彻,一篇文章肯定是不够的,在后面的文章中,我会继续探讨类似「Pipeline 不够健壮经常失败」,「使用 Pipeline 做安全方面任务」等问题,尽量覆盖 CI/CD 的常见问题,分享极狐 GitLab CI/CD 更多最佳实践,欢迎大家多多关注。
 毛超
毛超
极狐(GitLab) 研发工程师









