{{< details >}}
- Tier: 专业版, 旗舰版
- Offering: 私有化部署
{{< /details >}}
极狐GitLab 灾难恢复的主要使用场景是在计划外停机事件中确保业务连续性,但它可以与计划的故障切换结合使用,在不长时间停机的情况下在区域之间迁移你的极狐GitLab实例。
由于 Geo 站点之间的复制是异步的,计划故障切换需要一个维护窗口,在此期间阻止对主站点的更新。此窗口的长度由你的复制能力决定——当次要站点与主站点完全同步时,可以进行故障切换而不会丢失数据。
本文档假设你已经有一个完全配置和正常工作的 Geo 设置。在继续之前,完整阅读本文档和灾难恢复故障切换文档。计划的故障切换是一个重大操作,如果执行不当,数据丢失的风险很高。考虑练习该过程,直到你对执行必要步骤感到满意,并对能够准确执行它们充满信心。
不是所有的数据都会自动复制
如果你正在使用极狐GitLab中 Geo 不支持的任何功能,则必须做出单独的安排,以确保次要站点拥有该功能相关的任何数据的最新副本。这可能会显著延长所需的计划维护期。可以在复制的数据类型表中找到 Geo 支持的功能列表。
保持这一时期尽可能短的常见策略是使用 rsync 传输存储在文件中的数据。可以在维护窗口之前执行初始 rsync;随后在维护窗口内的最终传输则仅传输主站点和次要站点之间的更改。
关于有效使用 rsync 的 Git 仓库中心策略可以在移动仓库文档中找到;这些策略可以适用于任何其他基于文件的数据。
容器注册表
默认情况下,容器注册表不会自动复制到次要站点,需要手动配置,请参阅次要站点的容器注册表。
如果你正在当前主站点上使用本地存储来存储容器注册表,你可以将容器注册表对象 rsync 到你即将进行故障切换的次要站点:
# 从次要站点运行
rsync --archive --perms --delete root@<geo-primary>:/var/opt/gitlab/gitlab-rails/shared/registry/. /var/opt/gitlab/gitlab-rails/shared/registry
或者,你可以在主站点备份容器注册表,并将其恢复到次要站点:
-
在你的主站点上,仅备份注册表,并从备份中排除特定目录:
# 在 /var/opt/gitlab/backups 文件夹中创建备份 sudo gitlab-backup create SKIP=db,uploads,builds,artifacts,lfs,terraform_state,pages,repositories,packages -
将从你的主站点生成的备份 tarball 复制到你的次要站点上的
/var/opt/gitlab/backups文件夹中。 -
在你的次要站点上,按照恢复极狐GitLab文档恢复注册表。
预检
运行此命令以列出所有预检,并在计划故障切换之前自动检查复制和验证是否完成,以确保过程顺利进行:
gitlab-ctl promotion-preflight-checks
每个步骤的详细描述如下。
DNS TTL
如果你计划更新主域名 DNS 记录,你可能希望维护低 TTL 以确保 DNS 更改的快速传播。
对象存储
如果你有一个大型极狐GitLab安装或无法容忍停机,考虑在计划故障切换之前迁移到对象存储。这样做可以减少维护窗口的长度,并降低由于计划故障切换执行不当而导致的数据丢失风险。
在极狐GitLab 15.1 中,你可以选择允许极狐GitLab管理次要站点的对象存储复制。有关更多信息,请参阅对象存储复制。
审查每个次要站点的配置
数据库设置会自动复制到次要站点,但 /etc/gitlab/gitlab.rb 文件必须手动设置,并且各站点之间有所不同。如果在主站点启用了 Mattermost、OAuth 或 LDAP 集成等功能,而在次要站点上没有启用,这些功能在故障切换期间会丢失。
审查两个站点的 /etc/gitlab/gitlab.rb 文件,并确保次要站点支持主站点的所有功能,然后再计划故障切换。
运行系统检查
在主站点和次要站点上运行以下命令:
gitlab-rake gitlab:check
gitlab-rake gitlab:geo:check
如果任何站点报告任何故障,应在计划故障切换之前解决这些问题。
检查密钥和 SSH 主机密钥在节点之间是否匹配
SSH 主机密钥和 /etc/gitlab/gitlab-secrets.json 文件在所有节点上应该是相同的。通过在所有节点上运行以下命令并比较输出来检查:
sudo sha256sum /etc/ssh/ssh_host* /etc/gitlab/gitlab-secrets.json
如果任何文件不同,请手动复制极狐GitLab密钥并根据需要复制 SSH 主机密钥到次要站点。
检查是否为 HTTPS 安装了正确的证书
如果主站点和主站点访问的所有外部站点都使用公共 CA 签发的证书,则可以安全地跳过此步骤。
如果主站点使用自定义或自签名的 TLS 证书来保护入站连接,或者主站点连接到使用自定义或自签名证书的外部服务,则正确的证书也应安装在次要站点上。按照使用自定义证书的说明来配置次要站点。
确保 Geo 复制是最新的
维护窗口在 Geo 复制和验证完全完成之前不会结束。为了尽可能缩短窗口,你应该确保这些过程在主动使用期间尽可能接近 100%。
在次要站点上:
- 在左侧边栏底部,选择 管理员。
-
选择 Geo > 站点。 复制的对象(绿色显示)应接近 100%, 并且不应有故障(红色显示)。如果大量对象尚未复制(灰色显示),请考虑给站点更多时间完成。
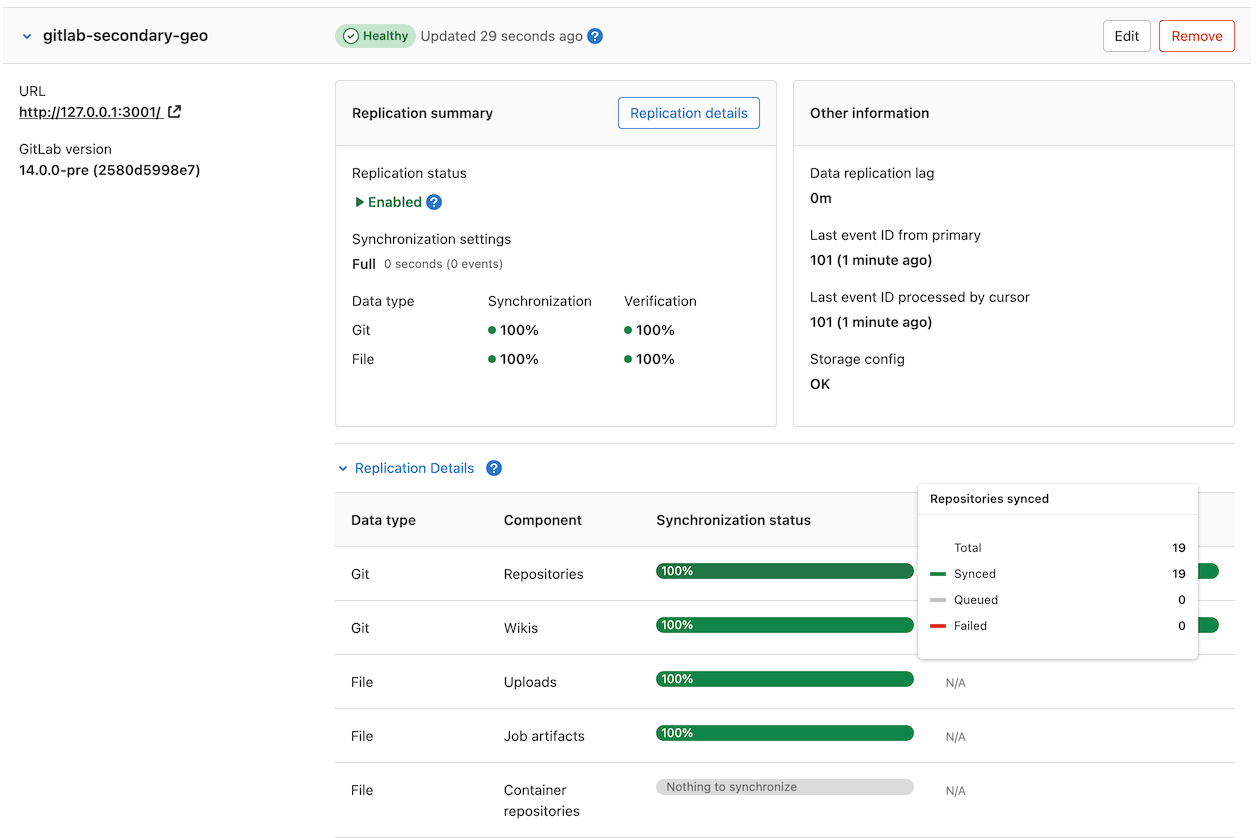
如果有任何对象无法复制,则应在计划维护窗口之前进行调查。计划故障切换后,任何未能复制的东西都会丢失。
复制失败的常见原因是在主站点上缺少数据——你可以通过从备份中恢复数据或删除对缺失数据的引用来解决这些故障。
验证复制数据的完整性
通知用户计划的维护
在主站点上:
- 在左侧边栏底部,选择 管理员。
- 选择 消息。
- 添加一条通知用户维护窗口的消息。 你可以在 Geo > 站点下检查以估计完成同步需要多长时间。
- 选择 添加广播消息。
Runner 故障切换
根据你的实例 URL 配置方式,可能需要额外的步骤以在故障切换后保持你的 runner 机群 100%。
用于注册 runners 的令牌应该在主实例或次要实例上工作。如果在故障切换后看到连接问题,可能是密钥在次要配置期间没有复制过来。你可以重置 runner 令牌,但是要注意,如果密钥不同步,你可能会遇到与 runner 无关的其他问题。
如果 runner 多次无法连接到极狐GitLab实例,它会在一段时间(默认 1 小时)内停止尝试连接。如果你想避免这种情况,在极狐GitLab实例可访问之前应该关闭 runner。请参阅check_interval 文档,以及配置选项 unhealthy_requests_limit 和 unhealthy_interval。
- 如果你正在使用我们的位置感知 URL,在旧的主站点从 DNS 配置中移除后,runners 应该自动连接到下一个最近的实例。
- 如果你使用的是独立 URL,则连接到当前主站点的任何 runner 需要更新以连接到新主站点,一旦升级。
- 如果你有任何 runners 连接到你的当前次要站点,请参阅在故障切换期间如何处理它们。
防止对主站点的更新
为了确保所有数据复制到次要站点,需要在主站点上禁用更新(写入请求):
- 在主站点上启用维护模式。
- 在左侧边栏底部,选择 管理员。
- 选择 监控 > 后台作业。
- 在 Sidekiq 仪表板上,选择 Cron。
- 选择
Disable All以禁用非 Geo 的周期性后台作业。 -
为以下 cronjobs 选择
Enable:geo_metrics_update_workergeo_prune_event_log_workergeo_verification_cron_workerrepository_check_worker
这会重新启用几个对计划故障切换成功完成至关重要的 cron 作业。
完成所有数据的复制和验证
- 如果你正在手动复制 Geo 未管理的任何数据,请立即触发最终复制过程。
- 在主站点上:
- 在左侧边栏底部,选择 管理员。
- 在左侧边栏,选择 监控 > 后台作业。
- 在 Sidekiq 仪表板上,选择 Queues,并等待除具有
geo名称的队列外所有队列下降到 0。 这些队列包含用户提交的工作;在完成之前进行故障切换会导致工作丢失。 -
在左侧边栏,选择 Geo > 站点,并等待你故障切换到的次要站点满足以下条件:
- 所有复制仪表达到 100% 复制,无故障。
- 所有验证仪表达到 100% 验证,无故障。
- 数据库复制延迟为 0 毫秒。
- Geo 日志游标是最新的(0 个事件落后)。
- 在次要站点上:
- 在左侧边栏底部,选择 管理员。
- 在左侧边栏,选择 监控 > 后台作业。
- 在 Sidekiq 仪表板上,选择 Queues,并等待所有
geo队列下降到 0 排队和 0 运行作业。 - 运行完整性检查,以验证文件存储中的 CI 产物、LFS 对象和上传的完整性。
此时,你的次要站点包含与主站点一样最新的副本,意味着故障切换时没有丢失任何内容。
升级次要站点
复制完成后,将次要站点升级为主站点。此过程会导致次要站点短暂停机,用户可能需要重新登录。如果你正确执行步骤,旧的主 Geo 站点应该仍然被禁用,用户流量应该转到新升级的站点。
完成升级后,维护窗口结束,你的新主站点现在开始与旧站点分离。如果此时出现问题,回退到旧的主站点是可能的,但可能会导致在此期间上传到新的主站点的任何数据丢失。
故障切换完成后,不要忘记删除广播消息。
最后,你可以将旧站点作为次要站点返回。