{{< details >}}
- Tier: 基础版, 专业版, 旗舰版
- Offering: JihuLab.com, 私有化部署
{{< /details >}}
CI/CD Pipelines 是 极狐GitLab CI/CD 的基础构建块。提高流水线的效率有助于节省开发人员的时间,这可以:
- 加速您的 DevOps 过程
- 降低成本
- 缩短开发反馈周期
通常,新团队或项目会从缓慢且低效的流水线开始,并通过反复试验逐步改进其配置。更好的方法是使用流水线功能立即提高效率,从而更快地获得软件开发生命周期。
首先确保您熟悉 极狐GitLab CI/CD 基础知识 并理解 快速入门指南。
识别瓶颈和常见故障
检查流水线效率低下的最简单指标是作业、阶段和流水线本身的总运行时间。总流水线持续时间受到以下因素的严重影响:
另一个需要注意的点与 极狐GitLab Runners 相关:
- runner 的可用性及其所提供的资源。
- 构建依赖项的安装时间和存储空间要求。
- 容器镜像大小。
- 网络延迟和连接缓慢。
流水线不必要地频繁失败也会导致开发生命周期减慢。您应该寻找失败作业的问题模式:
- 随机失败或产生不可靠测试结果的 flaky 单元测试。
- 测试覆盖率下降和代码质量与该行为相关。
- 可以安全忽略但却导致流水线停止的故障。
- 在长流水线的末尾失败的测试,实际上可以在更早的阶段进行,从而导致反馈延迟。
流水线分析
分析流水线的性能以寻找提高效率的方法。分析可以帮助识别 CI/CD 基础架构中的潜在阻碍因素。这包括分析:
- 作业负载。
- 执行时间中的瓶颈。
- 整体流水线架构。
了解并记录流水线工作流程非常重要,同时讨论可能的操作和更改。在 DevSecOps 生命周期中重构流水线可能需要团队之间的仔细互动。
流水线分析有助于识别成本效率问题。例如,托管在付费云服务上的 runners 可能会提供:
- 超出 CI/CD 流水线所需的资源,浪费资金。
- 资源不足,导致运行时间缓慢和浪费时间。
流水线洞察
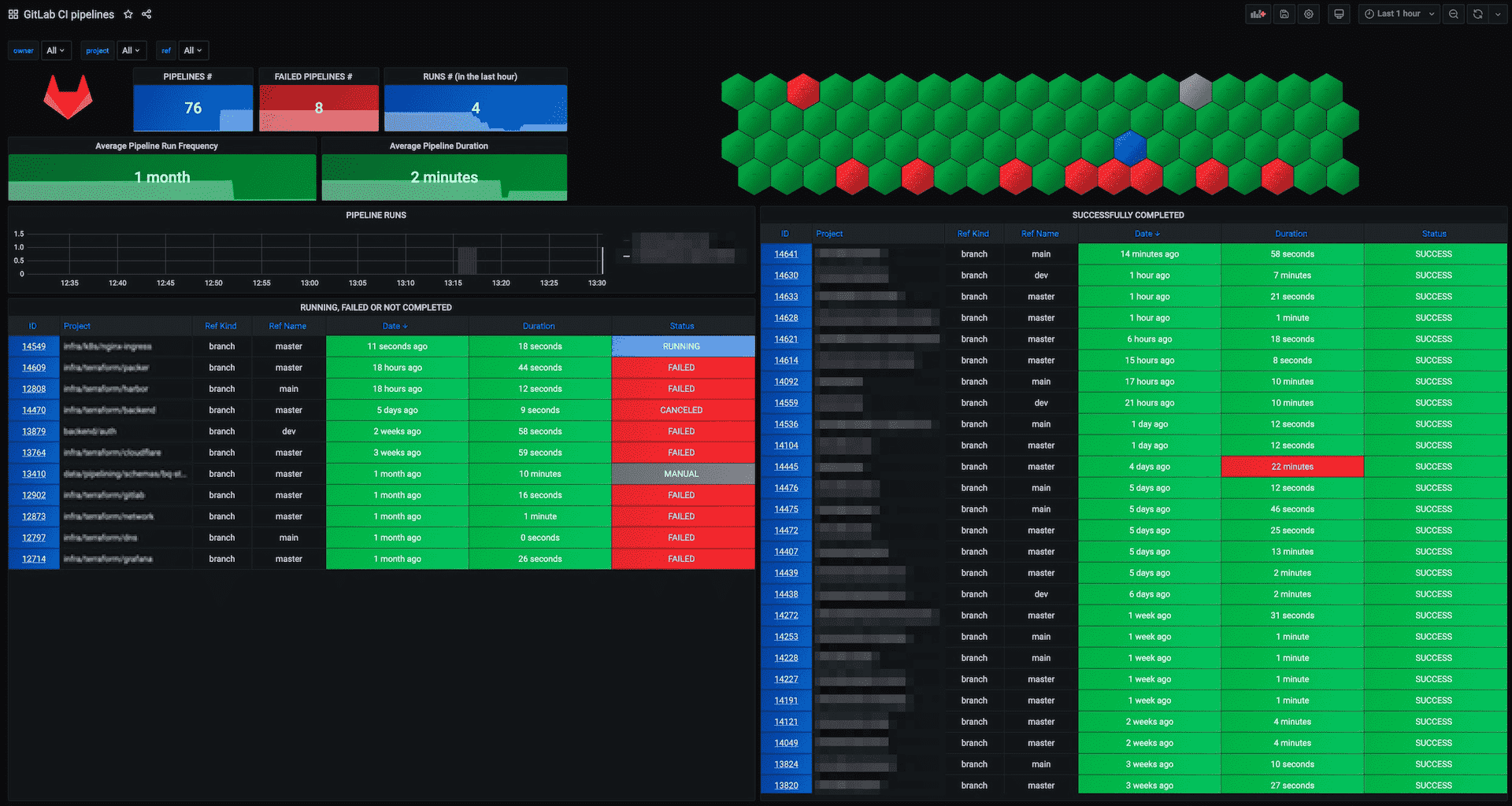
流水线成功和持续时间图表 提供有关流水线运行时间和失败作业计数的信息。
测试如 单元测试、集成测试、端到端测试、代码质量 测试和其他测试,确保问题通过 CI/CD 流水线自动发现。可能涉及许多流水线阶段,导致较长的运行时间。
您可以通过在同一阶段并行运行测试不同事物的作业来提高运行时间,减少整体运行时间。缺点是您需要更多 runner 同时运行以支持并行作业。
极狐GitLab 的测试级别 提供了一个涉及许多组件的复杂测试策略示例。
needs 依赖可视化
在完整流水线图中查看 needs 依赖可以帮助分析流水线中的关键路径并了解可能的阻碍因素。
流水线监控
全局流水线健康状况是一个关键指标,需与作业和流水线持续时间一起监控。CI/CD 分析 提供流水线健康的视觉表现。
实例管理员可以访问其他性能指标和自我监控。
您可以从 API 获取特定流水线健康指标。外部监控工具可以轮询 API 并验证流水线健康或收集长期 SLA 分析的指标。
例如,极狐GitLab CI Pipelines Exporter 用于 Prometheus,从 API 和流水线事件中获取指标。它可以自动检查项目中的分支并获取流水线状态和持续时间。结合 Grafana 仪表板,这有助于为您的运营团队构建可操作的视图。度量图表还可以嵌入到事件中,使问题解决更容易。此外,它还可以导出有关作业和环境的指标。
或者,您可以使用可以执行脚本的监控工具,例如 check_gitlab。
Runner 监控
您还可以在其主机系统上或 Kubernetes 等集群中监控 CI runners。这包括检查:
- 磁盘和磁盘 IO
- CPU 使用率
- 内存
- runner 进程资源
Prometheus Node Exporter 可以监控 Linux 主机上的 runner,而 kube-state-metrics 则在 Kubernetes 集群中运行。
您还可以使用云提供商测试极狐GitLab Runner 自动扩展,并定义离线时间以降低成本。
仪表板和事件管理
使用您现有的监控工具和仪表板来集成 CI/CD 流水线监控,或从头开始构建它们。确保运行时数据在团队中可操作且有用,并且运营/SRE 能够足够早地识别问题。事件管理 也可以在这里提供帮助,提供嵌入的度量图表和所有有价值的细节以分析问题。
存储使用
查看以下存储使用情况以帮助分析成本和效率:
流水线配置
在配置流水线时做出谨慎选择,以加快流水线速度并减少资源使用。这包括利用极狐GitLab CI/CD 内置的功能,使流水线运行得更快更高效。
减少作业运行频率
尝试找出哪些作业不需要在所有情况下运行,并使用流水线配置来阻止它们运行:
- 使用
interruptible关键字在旧流水线被新流水线取代时停止它们。 - 使用
rules跳过不需要的测试。例如,仅在前端代码发生更改时跳过后端测试。 - 减少非必要的计划流水线的运行频率。
- 将
cron调度均匀分布在时间上。
快速失败
确保在 CI/CD 流水线中尽早检测到错误。一个需要很长时间才能完成的作业会阻止流水线在作业完成前返回失败状态。
设计流水线,使得可以快速失败的作业运行得更早。例如,添加一个早期阶段,将语法、样式检查、Git 提交消息验证等作业移至该阶段。
决定是否重要的是长时间作业要提前运行,以便从更快的作业中获得快速反馈。初始故障可能会明确表明其余流水线不应运行,从而节省流水线资源。
needs 关键字
在基本配置中,作业总是等待更早阶段的所有其他作业完成后再运行。这是最简单的配置,但在大多数情况下也是最慢的。使用 needs 关键字的流水线 和 父/子流水线 更灵活,可以更高效,但也可能使流水线更难以理解和分析。
缓存
另一种优化方法是缓存依赖项。如果您的依赖项很少更改,例如 NodeJS /node_modules,缓存可以使流水线执行更快。
您可以使用 cache:when 在作业失败时仍缓存下载的依赖项。
Docker 镜像
下载和初始化 Docker 镜像可能是作业整体运行时间的重要组成部分。
如果 Docker 镜像减慢了作业执行速度,请分析基础镜像大小和到注册表的网络连接。如果极狐GitLab 在云中运行,寻找供应商提供的云容器注册表。此外,您可以利用极狐GitLab 容器注册表,极狐GitLab 实例可以比其他注册表更快地访问。
优化 Docker 镜像
构建优化的 Docker 镜像,因为大型 Docker 镜像占用大量空间,并且在连接速度较慢时需要很长时间才能下载。如果可能,避免为所有作业使用一个大型镜像。使用多个较小的镜像,每个镜像用于特定任务,可以更快地下载和运行。
尝试使用预安装软件的自定义 Docker 镜像。通常下载一个较大的预配置镜像比每次使用通用镜像并在其上安装软件要快得多。
减少 Docker 镜像大小的方法:
- 使用小型基础镜像,例如
debian-slim。 - 如果不严格需要,不要安装便捷工具,如 vim 或 curl。
- 创建专用开发镜像。
- 禁用由软件包安装的手册页和文档以节省空间。
- 减少
RUN层并合并软件安装步骤。 - 使用多阶段构建 将使用构建器模式的多个 Dockerfile 合并为一个 Dockerfile,从而减少镜像大小。
- 如果使用
apt,添加--no-install-recommends以避免不必要的软件包。 - 在结束时清理缓存和不再需要的文件。例如,对于 Debian 和 Ubuntu 使用
rm -rf /var/lib/apt/lists/*,或对于 RHEL 和 CentOS 使用yum clean all。 - 使用像 dive 或 DockerSlim 这样的工具来分析和缩小镜像。
为简化 Docker 镜像管理,您可以创建一个专用群组来管理 Docker 镜像,并使用 CI/CD 流水线测试、构建和发布它们。
测试、文档和学习
改进流水线是一个迭代过程。进行小的更改,监控效果,然后再次迭代。许多小的改进可以累积成流水线效率的大幅提升。
记录流水线设计和架构可能会有所帮助。您可以直接在极狐GitLab 仓库中使用 Markdown 中的 Mermaid 图表 来实现这一点。
在议题中记录 CI/CD 流水线问题和事件,包括所做的研究和找到的解决方案。这有助于新团队成员的入职,也有助于识别与 CI 流水线效率相关的重复问题。